
"Hoffnung ist keine Strategie."
Traditioneller SRE-Spruch

Abbildung 1: Wappen des Site Reliability Engineering Spezialisten: SREs
Es ist eine allgemein anerkannte Wahrheit, dass Systeme nicht von selbst laufen. Wie also sollte ein System – insbesondere ein komplexes Computersystem, das in grossem Massstab betrieben wird – betrieben werden?
Der Sysadmin-Ansatz von Site Reliability Engeneering für das Service-Management
In der Vergangenheit haben Unternehmen Systemadministratoren eingestellt, um komplexe Computersysteme zu betreiben.
Dieser Systemadministrator- oder Sysadmin-Ansatz beinhaltet die Zusammenstellung bestehender Software-Komponenten und deren Deployment, um gemeinsam einen Service zu erstellen. Sysadmins haben dann die Aufgabe, den Dienst zu betreiben und auf Ereignisse und Aktualisierungen zu reagieren, wenn diese auftreten. Wenn das System an Komplexität und Datenverkehr zunimmt und damit auch die Anzahl der Ereignisse und Aktualisierungen steigt, wächst das Team der Systemadministratoren, um die zusätzliche Arbeit zu bewältigen. Da die Rolle des Sysadmins deutlich andere Fähigkeiten erfordert als die der Produktentwickler, werden Entwickler und Sysadmins in getrennte Teams aufgeteilt: „Entwicklung“ und „Betrieb“ oder „Ops“. Hier sieht man schon die Geburtsstunde der DevOps Bewegung, aus der auch die des Site Reliability Engineering (SRE) hervorgegangen ist.
Das Sysadmin-Modell des Service-Managements hat mehrere Vorteile. Für Unternehmen, die entscheiden, wie sie einen Service betreiben und personell besetzen wollen, ist dieser Ansatz relativ einfach zu implementieren: Als bekanntes Branchenparadigma gibt es viele Beispiele, von denen man lernen und die man nachahmen kann. Ein relevanter Talentpool ist bereits weithin verfügbar. Eine Reihe von bestehenden Tools, Softwarekomponenten (von der Stange oder anderweitig) und Integrationsunternehmen sind verfügbar, um diese zusammengestellten Systeme zu betreiben, so dass ein neues Systemadministrator-Team das Rad nicht neu erfinden und ein System von Grund auf neu entwerfen muss.
Der Sysadmin-Ansatz (später wurde im DevOps oder auch SRE Ansatz erkannt, dass eine Trennung die Transparenz nicht fördert) und die damit einhergehende Trennung von Entwicklung und Betrieb hat eine Reihe von Nachteilen und Fallstricken. Diese lassen sich grob in zwei Kategorien einteilen: direkte Kosten und indirekte Kosten.
Direkte Kosten sind weder subtil noch zweideutig. Der Betrieb eines Dienstes mit einem Team, das auf manuelle Eingriffe sowohl für das Änderungsmanagement als auch für die Ereignisbehandlung angewiesen ist, wird teuer, wenn der Dienst und/oder der Datenverkehr zum Dienst wächst, da die Grösse des Teams notwendigerweise mit der vom System erzeugten Last skaliert.
Die indirekten Kosten der Trennung von Entwicklung und Betrieb können subtil sein, sind aber oft teurer für die Organisation als die direkten Kosten. Diese Kosten ergeben sich aus der Tatsache, dass die beiden Teams recht unterschiedliche Hintergründe, Fähigkeiten und Anreize haben. Sie verwenden ein unterschiedliches Vokabular, um Situationen zu beschreiben; sie haben unterschiedliche Annahmen über Risiken und technische Lösungsmöglichkeiten; sie haben unterschiedliche Annahmen über das angestrebte Niveau der Produktstabilität. Die Trennung zwischen den Gruppen kann leicht zu einer Trennung nicht nur der Anreize, sondern auch der Kommunikation, der Ziele und schliesslich des Vertrauens und des Respekts werden. Dieses Ergebnis ist eine Pathologie.
Traditionelle Betriebsteams und ihre Pendants in der Produktentwicklung geraten daher oft in Konflikt, am sichtbarsten bei der Frage, wie schnell Software für die Produktion freigegeben werden kann. Im Kern wollen die Entwicklungsteams neue Funktionen einführen und sehen, wie sie von den Benutzern angenommen werden. Im Kern wollen die Ops-Teams sicherstellen, dass der Dienst nicht ausfällt, während sie den Pager halten. Da die meisten Ausfälle durch irgendeine Art von Änderung verursacht werden – eine neue Konfiguration, die Einführung einer neuen Funktion oder eine neue Art von Benutzerverkehr – stehen die Ziele der beiden Teams grundsätzlich in Spannung zueinander.
Beide Gruppen verstehen, dass es inakzeptabel ist, ihre Interessen in möglichst nüchternen Begriffen zu formulieren („Wir wollen alles starten, jederzeit, ohne Behinderung“ versus „Wir wollen niemals etwas am System ändern, wenn es einmal funktioniert“). Und weil sich ihr Vokabular und ihre Risikoannahmen unterscheiden, greifen beide Gruppen oft auf eine bekannte Form von Grabenkämpfen zurück, um ihre Interessen durchzusetzen. Das Ops-Team versucht, das laufende System gegen das Risiko von Änderungen abzusichern, indem es Launch- und Change-Gates einführt. Launch-Reviews können zum Beispiel eine explizite Prüfung für jedes Problem enthalten, das jemals einen Ausfall in der Vergangenheit verursacht hat – das könnte eine beliebig lange Liste sein, wobei nicht alle Elemente gleichwertig sind. Das Entwicklerteam lernt schnell, wie es darauf reagieren kann. Sie haben weniger „Launches“ und mehr „Flag Flips“, „inkrementelle Updates“ oder „Cherrypicks“. Sie wenden Taktiken an, wie z.B. das Produkt aufzuteilen, so dass weniger Funktionen Gegenstand der Launch-Überprüfung sind.
Neue Rollen im Site Reliability Engineering: Site Reliability Engineer (SRE)
Site Reliability Engineering (SRE) ist ein softwaretechnischer Ansatz für den IT-Betrieb. SRE-Teams verwenden Software als Werkzeug, um Systeme zu verwalten, Probleme zu lösen und Betriebsaufgaben zu automatisieren.
Site Reliability Engineering (SRE) übernimmt die Aufgaben, die in der Vergangenheit von Operations-Teams – oft manuell – erledigt wurden, und übergibt sie stattdessen an Ingenieure oder Ops-Teams, die Software und Automatisierung einsetzen, um Probleme zu lösen und Produktionssysteme zu verwalten.

Abbildung 2: Google Site Reliability Engineering SRE Buch
SRE ist eine wertvolle Praxis bei der Erstellung skalierbarer und hoch zuverlässiger Softwaresysteme. Es hilft Ihnen, grosse Systeme durch Code zu verwalten, was für Sysadmins, die Tausende oder Hunderttausende von Maschinen verwalten, skalierbarer und nachhaltiger ist.
Das Konzept des Site-Reliability-Engineering stammt aus dem Google-Engineering-Team und wird Ben Treynor Sloss zugeschrieben.
SRE hilft Teams, ein Gleichgewicht zwischen der Freigabe neuer Funktionen und der Sicherstellung der Zuverlässigkeit für die Benutzer zu finden.
Standardisierung und Automatisierung sind 2 wichtige Komponenten des SRE-Modells. Site Reliability Engineers sollten immer nach Möglichkeiten zur Verbesserung und Automatisierung von Betriebsaufgaben suchen.
Auf diese Weise trägt SRE dazu bei, die Zuverlässigkeit eines Systems heute zu verbessern, während es gleichzeitig im Laufe der Zeit immer besser wird.
SRE unterstützt Teams, die von einem traditionellen Ansatz für den IT-Betrieb zu einem „Cloud-Native“ Ansatz wechseln.
Was macht ein Site Reliability Engineer?
Ein Site Reliability Engineer (SRE) ist eine einzigartige Rolle, die entweder einen Hintergrund als Softwareentwickler mit zusätzlicher Betriebserfahrung erfordert, oder als Sysadmin oder in einer IT-Betriebsrolle, die auch über Softwareentwicklungskenntnisse verfügt.
SRE-Teams sind dafür verantwortlich, wie Code bereitgestellt, konfiguriert und überwacht wird, sowie für die Verfügbarkeit, Latenz, das Änderungsmanagement, die Notfallreaktion und das Kapazitätsmanagement von Services in der Produktion.
Das Site Reliability Engineering hilft den Teams zu bestimmen, welche neuen Funktionen wann eingeführt werden können. Dazu werden Service-Level-Agreements (SLAs) verwendet, um die erforderliche Zuverlässigkeit des Systems durch Service-Level-Indikatoren (SLI) und Service-Level-Ziele (SLO) zu definieren.
Ein SLI ist ein definiertes Mass für bestimmte Aspekte der bereitgestellten Service-Levels. Zu den wichtigsten SLIs gehören Anfragelatenz, Verfügbarkeit, Fehlerrate und Systemdurchsatz. Ein SLO basiert auf dem Zielwert oder -bereich für einen bestimmten Service Level auf der Grundlage des SLI.
Auf Basis der als akzeptabel vereinbarten Ausfallzeit wird dann ein SLO für die erforderliche Systemzuverlässigkeit festgelegt. Dieses Ausfallzeitniveau wird als Fehlerbudget bezeichnet, die maximal zulässige Schwelle für Fehler und Ausfälle.
Bei SRE wird keine 100-prozentige Zuverlässigkeit erwartet; ein Ausfall wird eingeplant und akzeptiert.
Das Entwicklungsteam kann das Fehlerbudget „ausgeben“, wenn es eine neue Funktion freigibt. Anhand des SLO und des Fehlerbudgets kann das Entwicklungsteam bestimmen, ob ein Produkt oder ein Dienst auf der Grundlage des verfügbaren Fehlerbudgets eingeführt werden kann oder nicht.
Wenn ein Dienst innerhalb des Fehlerbudgets läuft, kann das Entwicklungsteam starten, wann immer es will, aber wenn das System derzeit zu viele Fehler hat oder länger ausfällt, als es das Fehlerbudget erlaubt, können keine neuen Starts stattfinden, bis die Fehler innerhalb des Budgets liegen.
Das Entwicklungsteam führt automatisierte Betriebstests durch, um die Zuverlässigkeit nachzuweisen.
Site Reliability Engineers teilen ihre Zeit zwischen Betriebsaufgaben und Projektarbeit auf. Laut den SRE Best Practices von Google darf ein Site Reliability Engineer nur maximal 50 % seiner Zeit für den Betrieb aufwenden, was überwacht werden sollte, um sicherzustellen, dass er nicht darüber hinausgeht.
Die restliche Zeit sollte für Entwicklungsaufgaben wie die Erstellung neuer Funktionen, die Skalierung des Systems und die Implementierung von Automatisierung verwendet werden.
Überschüssige operative Arbeit und schlecht funktionierende Dienste können an das Entwicklungsteam zurückverwiesen werden, anstatt dass der Site Reliability Engineer zu viel Zeit mit dem Betrieb einer Anwendung oder eines Dienstes verbringt.
Automatisierung ist ein wichtiger Teil der Rolle des Site Reliability Engineers. Wenn sie wiederholt mit einem Problem zu tun haben, werden sie eine Lösung automatisieren. Dies trägt auch dazu bei, dass die Betriebsarbeiten bei der Hälfte ihrer Arbeitsbelastung bleiben.
Die Aufrechterhaltung des Gleichgewichts zwischen Betrieb und Entwicklungsarbeit ist eine Schlüsselkomponente von Site Reliability Engineering (SRE).
DevOps vs. Site Reliability Engineering
DevOps ist ein Ansatz für Kultur, Automatisierung und Plattformdesign, der darauf abzielt, den Geschäftswert und die Reaktionsfähigkeit durch schnelle und qualitativ hochwertige Servicebereitstellung zu erhöhen. SRE kann als eine Implementierung von DevOps betrachtet werden.

Abbildung 3: Site Reliability Engineering vs DevOps
Wie bei DevOps geht es bei SRE um Teamkultur und Beziehungen. Sowohl SRE als auch DevOps arbeiten daran, die Lücke zwischen Entwicklungs- und Betriebsteams zu schliessen, um Services schneller bereitzustellen.
Kürzere Lebenszyklen bei der Anwendungsentwicklung, verbesserte Servicequalität und -zuverlässigkeit sowie eine geringere IT-Zeit pro entwickelter Anwendung sind Vorteile, die sowohl durch DevOps- als auch durch SRE-Praktiken erzielt werden können.
SRE ist anders, weil es sich auf Site Reliability Engineers innerhalb des Entwicklungsteams verlässt, die auch einen operativen Hintergrund haben, um Kommunikations- und Workflow-Probleme zu beseitigen.
Die Rolle des Site Reliability Engineers selbst kombiniert die Fähigkeiten von Entwicklerteams und Betriebsteams, indem sie eine Überschneidung der Verantwortlichkeiten erfordert.
SRE kann DevOps-Teams helfen, deren Entwickler mit Operations-Aufgaben überfordert sind und jemanden mit spezielleren Ops-Kenntnissen benötigen.
In Bezug auf Code und neue Funktionen konzentriert sich DevOps darauf, die Entwicklungspipeline effizient zu durchlaufen, während sich SRE darauf konzentriert, die Zuverlässigkeit der Website mit der Erstellung neuer Funktionen in Einklang zu bringen.
Moderne Anwendungsplattformen, die auf Container-Technologie, Kubernetes und Microservices basieren, sind entscheidend für DevOps-Praktiken und helfen bei der Bereitstellung sicherer und innovativer Software-Services.
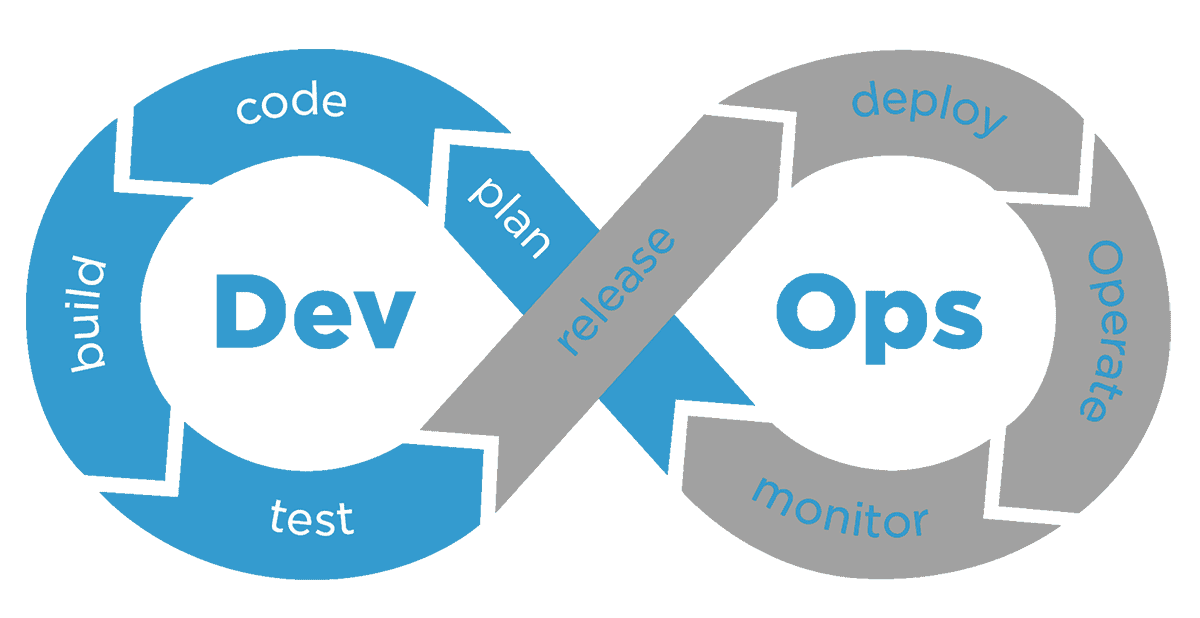
Abbildung 4: DevOps Lifecycle
Wie lange dauert der Kurs Site Reliability Engineering?

Abbildung 5: Site Reliability Engineering SRE Foundation Zertifikat
Glenfis bietet Kurse an, in denen die Grundlagen von Site Reliability Engineering erlernt werden. Ein solcher Kurs dauert in der Regel zwei Tage. Neben Schulungen in den Räumlichkeiten der Glenfis AG in Zürich gibt es SRE Foundation auch als Online-Kurs.
Bei entsprechender Teilnehmerzahl bieten sich auch Inhouse-Schulungen bei direkt vor Ort an. Glenfis organisiert diese auf Wunsch. In der Regel finden sie ab sechs teilnehmenden Personen statt. Zum Abschluss erhalten die Teilnehmer das SRE Zertifikat des DevOps Institutes.
Jetzt mit uns Kontakt aufnehmen, falls wir das Interesse an eine Schulung zum SRE Foundation geweckt haben.
Der Site-Reliability Engineering Kurs ist in 8 Module aufgeteilt und behandelt folgende Themen:
▪ Modul 1: Site Reliability Engineering Principles & Practices
▪ Modul 2: Service Level Objectives & Error Budgets
▪ Modul 3: Reducing Toil
▪ Modul 4: Monitoring & Service Level Indicators
▪ Modul 5: Site Reliability Engineering Tools & Automation
▪ Modul 6: Anti-Fragility & Learning from Failure
▪ Modul 7: Organizational Impact of SRE
▪ Modul 8: SRE, Other Frameworks, The Future
Ziele
▪ Kennenlernen des Site Reliability Engineering (SRE) Ansatzes und Gewinnen eines Grundverständnisses
▪ Die Wechselbeziehung von SRE mit DevOps und anderen populären Rahmenwerken verstehen
▪ Service Level Objectives (SLO) und Service Level Indicators (SLI) verstehen und anwenden
▪ Continuous Delivery als zentrale Rolle bei Einsatz von SRE anwenden und Vorstellen der Tool-Landschaft
▪ Vorstellung von SRE-Werkzeugen und Automatisierungstechniken unter Berücksichtigung von Security Vorgaben
▪ Warum sich Organisationen für SRE entscheiden und welche organisatorische Auswirkungen SRE in Unternehmen haben
Voraussetzungen
▪ Keine formellen Voraussetzungen
▪ Erfahrungen als Softwareentwickler, IT-Experte, Scrum-Master oder Operations Engineer sind von Vorteil
Zielgruppe
▪ Jeder, der an moderner IT-Führung und organisatorischen Veränderungen interessiert ist
▪ Business Manager
▪ Anwender von DevOps Praktiken
▪ IT-Manager & Berater
▪ Scrum-Master
▪ Software-Ingenieure